«Выглядит похоже». Как работает перцептивный хэш
За последние несколько месяцев несколько человек спросили меня, как работает TinEye и как в принципе работает поиск похожих картинок.
По правде говоря, я не знаю, как работает поисковик TinEye. Он не раскрывает деталей используемого алгоритма(-ов). Но глядя на поисковую выдачу, я могу сделать вывод о работе какой-то формы перцептивного хэш-алгоритма.
Это восприятие!
Перцептивные хэш-алгоритмы описывают класс функций для генерации сравнимых хэшей. Характеристики изображения используются для генерации индивидуального (но не уникального) отпечатка, и эти отпечатки можно сравнивать друг с другом.
Перцептивные хэши — это другая концепция по сравнению с криптографическими хэш-функциями вроде MD5 и SHA1. В криптографии каждый хэш является случайным. Данные, которые используются для генерации хэша, выполняют роль источника случайных чисел, так что одинаковые данные дадут одинаковый результат, а разные данные — разный результат. Из сравнения двух хэшей SHA1 на самом деле можно сделать только два вывода. Если хэши отличаются, значит, данные разные. Если хэши совпадают, то и данные, скорее всего, одинаковые (поскольку существует вероятность коллизий, то одинаковые хэши не гарантируют совпадения данных). В отличие от них, перцептивные хэши можно сравнивать между собой и делать вывод о степени различия двух наборов данных.
Все алгоритмы вычисления перцептивного хэша, которые я видел, обладают одинаковыми базовыми свойствами: картинки можно изменять в размере, менять соотношение сторон и даже слегка менять цветовые характеристики (яркость, контраст и т.д.), но они всё равно совпадают по хэшу. Те же свойства проявляет TinEye (но они делают больше, об этом я расскажу ниже).
Выглядит неплохо
Как получить перцептивный хэш? Для этого имеется несколько распространённых алгоритмов, и все они довольно простые (я всегда удивлялся, как самые известные алгоритмы дают эффект, если они настолько просты!). Одна из простейших хэш-функций отображает среднее значение низких частот.
В изображениях высокие частоты обеспечивают детализацию, а низкие частоты показывают структуру. Большая, детализированная фотография содержит много высоких частот. В очень маленькой картинке нет деталей, так что она целиком состоит из низких частот. Чтобы продемонстрировать работу хэш-функции по среднему, я возьму фотографию моей следующей жены Элисон Ханниган.

1. Уменьшить размер. Самый быстрый способ избавиться от высоких частот — уменьшить изображение. В данном случае мы уменьшаем его до 8х8, так что общее число пикселей составляет 64. Можно не заботиться о пропорциях, просто загоняйте его в квадрат восемь на восемь. Таким образом, хэш будет соответствовать всем вариантам изображения, независимо от размера и соотношения сторон.
 = = 
2. Убрать цвет. Маленькое изображение переводится в градации серого, так что хэш уменьшается втрое: с 64 пикселей (64 значения красного, 64 зелёного и 64 синего) всего до 64 значений цвета.
3. Найти среднее. Вычислите среднее значение для всех 64 цветов.
4. Цепочка битов. Это самое забавное: для каждого цвета вы получаете 1 или 0 в зависимости от того, он больше или меньше среднего.
5. Постройте хэш. Переведите 64 отдельных бита в одно 64-битное значение. Порядок не имеет значения, если он сохраняется постоянным (я записываю биты слева направо, сверху вниз).
 = = 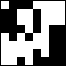 = 8f373714acfcf4d0 = 8f373714acfcf4d0
Итоговый хэш не изменится, если картинку масштабировать, сжать или растянуть. Изменение яркости или контраста, или даже манипуляции с цветами тоже сильно не повлияет на результат. И самое главное: такой алгоритм очень быстрый!
Если вам нужно сравнить две картинки, то просто строите хэш для каждой из них и подсчитываете количество разных битов (это расстояние Хэмминга). Нулевое расстояние означает, что это, скорее всего, одинаковые картинки (или вариации одного изображения). Дистанция 5 означает, что картинки в чём-то отличаются, но в целом всё равно довольно близки друг к другу. Если дистанция 10 или больше, то это, вероятно, совершенно разные изображения.
Пробуем pHash
Хэш по среднему простой и быстрый, но он даёт сбои. Например, может не найти дубликат картинки после гамма-коррекции или изменения цветовой гистограммы. Это объясняется тем, что цвета меняются в нелинейной масштабе, так что смещается положение «среднего» и многие биты меняют свои значения.
В хэш-функции pHash используется более надёжный алгоритм (вообще-то, я использую собственный вариант этого алгоритма, но концепция та же самая). Метод pHash заключается в доведении идеи средних значений до крайности, применив дискретное косинусное преобразование (DCT) для устранения высоких частот.
1. Уменьшить размер. Как и в случае хэша по среднему, pHash работает на маленьком размере картинки. Однако, здесь изображение больше, чем 8х8, вот 32x32 хороший размер. На самом деле это делается ради упрощения DCT, а не для устранения высоких частот.

2. Убрать цвет. Аналогично, цветовые каналы убирают, чтобы упростить дальнейшие вычисления.
3. Запустить дискретное косинусное преобразование. DCT разбивает картинку на набор частот и векторов. В то время как алгоритм JPEG прогоняет DCT на блоках 8x8, в данном алгоритме DCT работает на 32x32.
4. Сократить DCT. Это магический шаг. В то время как первоначальный блок был 32x32, сохраните только левый верхний блок 8x8. В нём содержатся самые низкие частоты из картинки.
5. Вычислить среднее значение. Как и в хэше по среднему, здесь вычисляется среднее значение DCT, оно вычисляется на блоке 8x8 и нужно исключить из расчёта самый первый коэффициент, чтобы убрать из описания хэша пустую информацию, например, одинаковые цвета.
6. Ещё сократить DCT. Тоже магический шаг. Присвойте каждому из 64 DCT-значений 0 или 1 в зависимости от того, оно больше или меньше среднего. Такой вариант уже выдержит без проблем гамма-коррекцию или изменение гистограммы.
7. Постройте хэш. 64 бита превращаются в 64-битное значение, здесь тоже порядок не имеет значения. Чтобы посмотреть, на что похож отпечаток визуально, можно присвоить каждому пикселю значения +255 и -255, в зависимости от того, там 1 или 0, и преобразовать DCT 32x32 (с нулями для высоких частот) обратно в изображение 32x32.
 = 8a0303769b3ec8cd = 8a0303769b3ec8cd
На первый взгляд картинка кажется бессмысленным набором шарообразных очертаний, но если присмотреться, то можно заметить, что тёмные области соответствуют тем же областям на фотографии (причёска и полоса на заднем фоне в правой части фотографии.
Как и в хэше по среднему, значения pHash можно сравнивать между собой с помощью того же алгоритма расстояния Хэмминга (сравнивается значение каждого бита и подсчитывается количество отличий).
Лучший в своём классе?
Поскольку я плотно занимаюсь экспертизой цифровых фотографий и работаю с гигантскими архивами изображений, то мне нужен инструмент для поиска одинаковых картинок. Так что я сделал такой поисковик, в котором используется несколько перцептивных хэш-алгоритмов. Как показывает мой богатый, хотя и ненаучный опыт, хэш-функция по среднему работает гораздо быстрее pHash и она отлично подходит, если вы ищете что-то конкретное. Например, если у меня есть крохотная иконка фотографии и я точно знаю, что где-то в коллекции хранится полноразмерный оригинал, то хэш по среднему быстро его найдёт. Однако, если с изображением осуществляли какие-то манипуляции, например, добавили текст или приклеили новое лицо, то он уже вряд ли справится, тогда как pHash хоть и медленнее, но гораздо более терпимо относится к незначительным модификациям изображения (менее 25% площади).
И ещё раз, если вы держите сервис вроде TinEye, то не будете каждый раз запускать pHash. Я полагаю, что у них есть база данных с заранее рассчитанными значениями хэшей. Основная функция сравнения изображений работает чрезвычайно быстро (есть некоторые способы сильно оптимизировать вычисление расстояние Хэмминга). Так что вычисление хэша — это одноразовая задача, и выполнять миллионы операций сравнения за пару секунд (на одном компьютере) вполне реально.
Разновидности
Существуют разновидности перцептивного хэш-алгоритма, которые также повышают быстродействие. Например, изображение можно обрезать перед тем как уменьшать размер. В этом случае потеря информации вокруг основной части изображения не играет особой роли. Кроме того, картинку можно поделить на части. Например, если у вас работает алгоритм распознавания лиц, то можно вычислять хэш для каждого лица (я подозреваю, что алгоритм TinEye делает нечто подобное).
Другие разновидности могут анализировать общее распределение цвета (например, её волосы более красные, чем синие или зелёные, а фон скорее светлый, чем тёмный) или относительно взаиморасположение линий.
Если вы можете сравнивать картинки, то перед вами открываются совершенно новые перспективы. Например, поисковик GazoPa позволяет рисовать картинку на экране. Как и в случае с TinEye, я не знаю всех деталей их алгоритма, но похоже на какой-то вариант перцептивного хэша. И поскольку хэш-функция сводит всё что угодно на низкие частоты, то мой кривой рисунок трёх фигурок с ручками-палочками может сравниться с другими изображениями, в том числе с фотографиями, на которых изображены трое людей.
Взято с http://habrahabr.ru/blogs/image_processing/120562/
|
|